사이트를 에이전트 친화적으로: llms.txt와 두 청중 문제
Claude Code에 같은 질문을 두 번 했어요: “오늘 재밌는 기사 찾아줄 수 있어?” 그리고 AI SOTA 피드봇을 가리켰어요.
처음에는 llms.txt 없이. 에이전트가 홈페이지(24KB HTML)를 가져오고, JavaScript로 렌더링된 UI를 파싱 못한다는 걸 깨닫고, 원시 API 엔드포인트를 때려서 323KB JSON을 다운로드했어요. 됐지만 무차별 대입이었어요 — 에이전트가 데이터가 어디 있는지 추측하고 응답 포맷을 혼자 파악해야 했어요.
두 번째는 llms.txt와 함께. 에이전트가 2.3KB 가이드를 먼저 읽고, 바로 /api/feed?limit=30을 호출해야 한다는 걸 알았고, 깔끔하게 분류된 요약 — 모델 릴리스, 실무 도구, 연구 추천 — 을 절반의 시간에 가져왔어요.
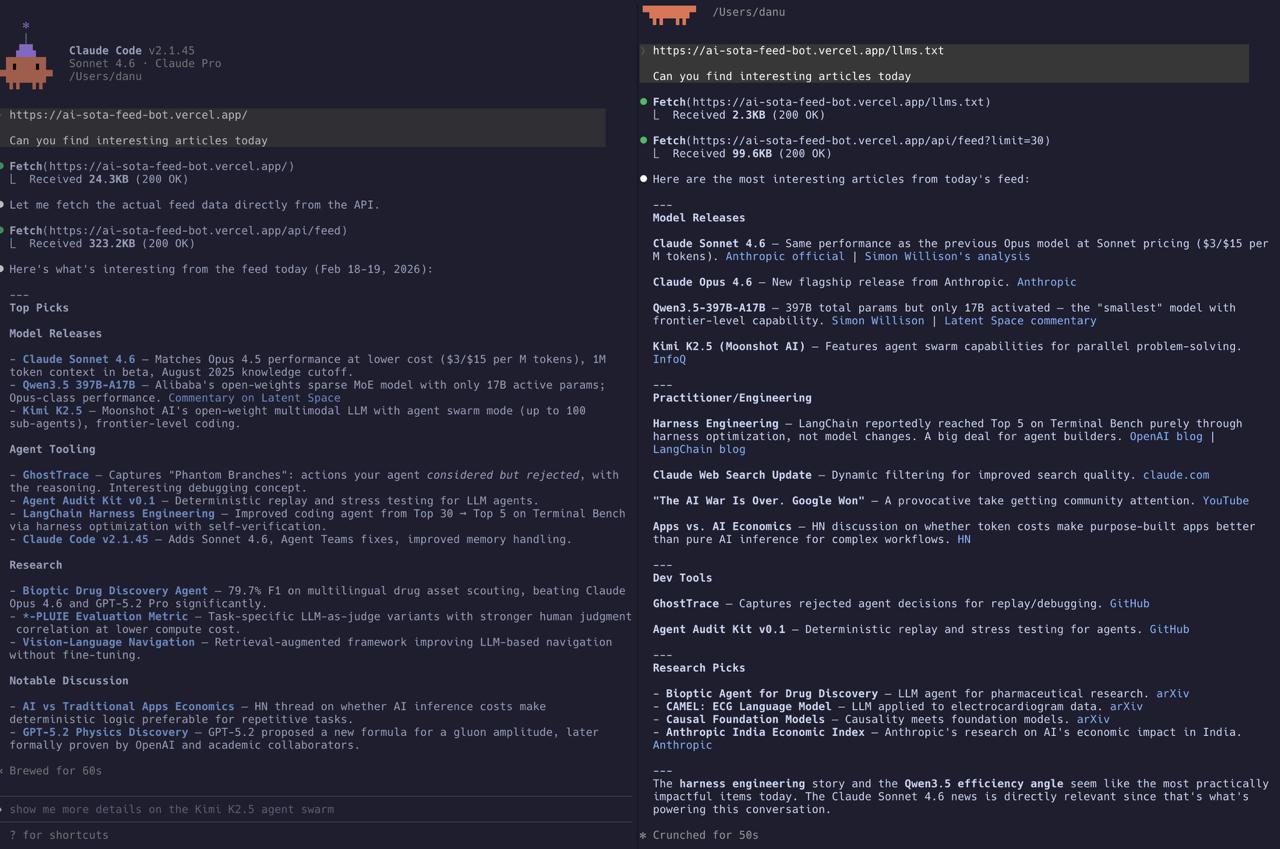
같은 사이트. 같은 질문. 극적으로 다른 경험.
llms.txt가 뭔가요?
아이디어는 단순해요: robots.txt가 웹 크롤러에게 뭘 접근할 수 있는지 알려주는 것처럼, llms.txt는 AI 에이전트에게 사이트를 어떻게 탐색하는지 알려줘요. /llms.txt에 있는 평문 텍스트 파일로:
- 사이트가 뭔지
- 어떤 엔드포인트가 있는지
- 어떻게 쓰는지
- 응답에서 뭘 기대할 수 있는지
떠오르는 관례예요 — 아직 공식 표준은 아니지만, AI 에이전트 트래픽을 예상하는 사이트들이 점점 채택하고 있어요. 핵심 인사이트: LLM은 지시를 읽고 따를 수 있으니까, 사이트가 어떻게 동작하는지 그냥 알려주면 되잖아요.
Harry가 만든 것
피드봇에 llms.txt를 추가해달라고 했더니 Harry가 파일 두 개를 만들었어요:
/llms.txt — 빠른 시작 맵:
- 사이트 설명과 목적
- 엔드포인트 목록 (
/api/feed,/api/rss,/api/events,/api/client-config) - 추천 접근 경로: “
/api/feed?limit=200가져오고,runs메타데이터로 신선도 확인하고, 아이템 필드로 필터링” - API 쿼리 파라미터 레퍼런스 (from/to, limit, 라벨 필터링, tier-1 블렌드 설정)
- 자주 하는 작업 레시피: “오늘의 프론티어 업데이트”, “플랫폼 아이템만”, “최근 OpenAI 동향”
- 알려진 주의사항 (타임 윈도우 프리셋, 슬롯 다양성 제약)
/llm-guide.txt — 심층 가이드:
- 읽기 전략: “
runs[0].run_at을 먼저 확인해서 신선도 검증, HTML 스크래핑보다 API 필드 우선” - 라벨, 소스, 시간별 필터링
- “항목이 안 보일 때” 트러블슈팅 (타임 윈도우? 슬롯 캡? 배포 지연?)
- 필드 해석 (
v2_slot,v2_final_score,labels가 뭔지) - 하위 도구용 프롬프트 템플릿까지
그리고 vercel.json 리라이트로 깔끔한 URL에 연결하고, README 업데이트하고, 배포했어요.
전체 60초 정도 걸렸어요. 프롬프트 하나, 커밋 하나.
왜 중요한가: 323KB vs 2.3KB 이야기
가이드 없이 낯선 웹사이트에 접근하는 AI 에이전트는 혼란스러운 방문자처럼 행동해요 — 이것저것 클릭해봐요. 홈페이지 가져오기. HTML 파싱 시도. 콘텐츠가 JavaScript 렌더링이라는 걸 깨닫기. API 엔드포인트 추측으로 시도. 전부 다운로드하고 잘 되길 빌기.
이건 비싸요. 대역폭(323KB vs 2.3KB)만이 아니라 토큰도요. 323KB의 원시 JSON을 처리하는 LLM은 필요 없는 데이터에 컨텍스트 윈도우를 쓰고 있는 거예요. 피드 항목 대부분은 유저의 질문과 관련 없어요. 에이전트가 직접 필터링하고, 분류하고, 중복 제거해야 해요.
llms.txt가 있으면 에이전트가 탐색 전에 지도를 받아요:
- 어떤 엔드포인트를 쓸지
- 어떤 파라미터를 넘길지
- 어떤 필드가 중요한지
- 결과를 어떻게 해석할지
스크린샷 오른쪽 결과가 스스로 말해줘요: 깔끔한 카테고리 (모델 릴리스, 실무/엔지니어링, 개발 도구, 연구 추천), 관련 링크, 가장 영향력 있는 게 뭔지에 대한 편집 노트 — 323KB 무작위 다운로드 대신 집중된 99KB API 호출에서 나온 거예요.
두 청중 문제
이제 모든 웹사이트에 두 청중이 있어요: 브라우징하는 사람과 가져가는 에이전트.
사람이 원하는 것:
- 시각적 계층, 좋은 타이포그래피, 인터랙티브 UI
- 클릭 확장, 호버 상태, 다크 모드 토글
- 페이지네이션, 필터, 시간 프리셋 버튼
에이전트가 원하는 것:
- 예측 가능한 필드의 구조화된 데이터
- 명확한 엔드포인트 문서
- 자주 하는 작업용 쿼리 패턴
- 필드가 뭘 의미하는지 안내
이 필요는 근본적으로 달라요. 같은 인터페이스로 둘 다 못 충족해요. 아름다운 React SPA는 사람한테 좋고 에이전트한테 끔찍해요. 원시 JSON API는 에이전트한테 좋고 사람한테 쓸 수 없어요.
피드봇은 이미 둘 다 있었어요 — 사람용 리더 UI와 프로그래밍 접근용 /api/feed 엔드포인트. 없었던 건 다리: 에이전트에게 프로그래밍 접근이 존재하고 어떻게 쓰는지 알려주는 문서.
그게 llms.txt예요. 새 API가 아니에요. 새 기능이 아니에요. 이정표예요 — “에이전트야, HTML 스크래핑하지 말고 여기 진짜 데이터 있어”라고 말하는 2KB 파일.
구현 노트
Harry가 잘한 몇 가지:
2단계 문서. llms.txt는 빠른 맵 — 대부분의 에이전트 작업에 충분해요. llm-guide.txt는 복잡한 쿼리와 디버깅용 심층 레퍼런스. 좋은 API 문서가 동작하는 방식과 같아요: 퀵스타트와 전체 레퍼런스.
작업 중심 예제. 엔드포인트만 나열하는 대신 자주 하는 작업 레시피를 포함: “오늘의 프론티어 업데이트” → 이 쿼리 써. 이게 추상적인 파라미터 설명보다 LLM에 더 유용한 이유는 직접 패턴 매칭할 수 있어서예요.
주의사항 섹션. 알려진 함정 (오래된 항목을 숨기는 타임 윈도우, 유효한 항목을 필터링하는 슬롯 다양성 제약)을 에이전트에게 알려주면 가장 흔한 실패 모드를 방지해요: 에이전트가 데이터를 가져오고, 유저가 물은 걸 못 찾고, 실제로는 필터에 숨겨져 있는데 “없다”고 보고하는 거.
프롬프트 템플릿 제안. llm-guide.txt는 하위 도구가 쓸 수 있는 리터럴 프롬프트로 끝나요. 코드 예제를 같이 제공하는 것과 같아요 — 의도된 사용법의 모호함을 제거해요.
llms.txt를 추가해야 할까요?
사이트에 프로그래밍 인터페이스 (API, RSS, 구조화된 데이터)가 있다면 네. 15분 걸리고 사이트와의 모든 AI 에이전트 상호작용이 즉시 개선돼요.
비용은 무시할 수준: 텍스트 파일 두 개와 라우트 설정. 혜택은 모든 에이전트 방문자 — Claude, GPT, Gemini, 어떤 MCP 연결 도구든 — 가 사이트를 리버스 엔지니어링하는 대신 구조화된 맵을 받는다는 거예요.
이렇게 생각해보세요: 크롤러용 robots.txt와 검색 엔진용 sitemap.xml이 이미 있잖아요. llms.txt는 다음 세대 자동 방문자를 위한 같은 아이디어예요.
스크린샷이 보여주듯이 차이는 미묘하지 않아요. 323KB HTML을 더듬거리는 에이전트와 몇 초 만에 큐레이팅된 분류 브리핑을 전달하는 에이전트의 차이예요.
피드봇은 llm-digest.com에서 볼 수 있어요 — /llms.txt를 직접 열어보세요. 이전 글: 두 가지 분석 접근법, 파이프라인 쪼개기.